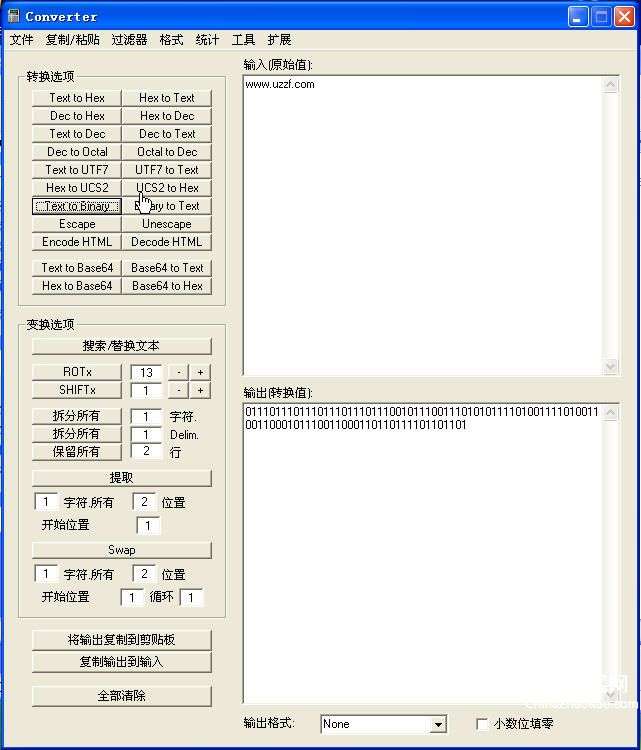
unicode编码转换器
成考报名 发布时间:05-17 阅读:
java中文转换Unicode编码
unicode编码转换器(一)
Java中文Unicode中文转换 转换背景:
把中文转换成Unicode编码再直接输出,程序解析XML,properties,以及JS打印提示信息后再把Unicode编码转回中文就没有问题了。
提供两种方法把中文转换成Unicode编码:
第一种办法:Eclipse中JS转换法
1. web项目中随便新建一个 *.js文件,将文件的编码属性设置为utf8 (右击文件从弹出菜单中选择“properties”在弹出的属性对话框中设置“Text file encoding”选项)
2. 打开新建的*.js文件,输入: “要转换的汉字”.
3. 按下Ctrl+Shift+F 或右键点击文件内容从弹出菜单中选择“Format Document”选型,效果出来了。
总结:必须将汉字放到””中间,否则不转换.
^_^
第二种办法:JAVA程序实现法
public class CharacterSetToolkit {
/** Creates a new instance of CharacterSetToolkit */
public CharacterSetToolkit() {
}
private static final char[] hexDigit = {
'0','1','2','3','4','5','6','7','8','9','A','B','C','D','E','F' };
private static char toHex(int nibble) {
return hexDigit[(nibble & 0xF)];
}
/**
* 将字符串编码成 Unicode 。
* @param theString 待转换成Unicode编码的字符串。
* @param escapeSpace 是否忽略空格。
* @return 返回转换后Unicode编码的字符串。
*/
public static String toUnicode(String theString, boolean escapeSpace) {
int len = theString.length();
int bufLen = len * 2;
if (bufLen < 0) {
bufLen = Integer.MAX_VALUE;
}
StringBuffer outBuffer = new StringBuffer(bufLen);
for(int x=0; x<len; x++) {
char aChar = theString.charAt(x);
// Handle common case first, selecting largest block that // avoids the specials below
if ((aChar > 61) && (aChar < 127)) {
if (aChar == '\\') {
outBuffer.append('\\'); outBuffer.append('\\'); continue;
}
outBuffer.append(aChar);
continue;
}
switch(aChar) {
case ' ':
if (x == 0 || escapeSpace)
outBuffer.append('\\');
outBuffer.append(' ');
break;
case '\t':outBuffer.append('\\'); outBuffer.append('t'); break;
case '\n':outBuffer.append('\\'); outBuffer.append('n'); break;
case '\r':outBuffer.append('\\'); outBuffer.append('r'); break;
case '\f':outBuffer.append('\\'); outBuffer.append('f'); break;
case '=': // Fall through
case ':': // Fall through
case '#': // Fall through
case '!':
outBuffer.append('\\'); outBuffer.append(aChar); break;
default:
if ((aChar < 0x0020) || (aChar > 0x007e)) {
outBuffer.append('\\');
outBuffer.append('u');
outBuffer.append(toHex((aChar >> 12) & 0xF)); outBuffer.append(toHex((aChar >> 8) & 0xF)); outBuffer.append(toHex((aChar >> 4) & 0xF));
outBuffer.append(toHex( aChar & 0xF)); } else {
outBuffer.append(aChar);
}
}
}
return outBuffer.toString();
}
/**
* 从 Unicode 码转换成编码前的特殊字符串。
* @param in Unicode编码的字符数组。
* @param off 转换的起始偏移量。
* @param len 转换的字符长度。
* @param convtBuf 转换的缓存字符数组。
* @return 完成转换,返回编码前的特殊字符串。
*/
public String fromUnicode(char[] in, int off, int len, char[] convtBuf) {
if (convtBuf.length < len) {
int newLen = len * 2;
if (newLen < 0) {
newLen = Integer.MAX_VALUE;
}
convtBuf = new char[newLen];
}
char aChar;
char[] out = convtBuf;
int outLen = 0;
int end = off + len;
while (off < end) {
aChar = in[off++];
if (aChar == '\\') {
aChar = in[off++];
if (aChar == 'u') {
// Read the xxxx
int value = 0;
for (int i = 0; i < 4; i++) {
aChar = in[off++];
switch (aChar) {
case '0':
case '1':
case '2':
case '3':
case '4':
case '5':
case '6':
case '7':
case '8':
case '9':
value = (value << 4) + aChar - '0'; break;
case 'a':
case 'b':
case 'c':
case 'd':【unicode编码转换器】
case 'e':
case 'f':
value = (value << 4) + 10 + aChar - 'a'; break;
case 'A':
case 'B':
case 'C':
case 'D':
case 'E':
case 'F':
value = (value << 4) + 10 + aChar - 'A'; break;
default:
throw new IllegalArgumentException( "Malformed \\uxxxx encoding."); }
}
out[outLen++] = (char) value;
} else {
if (aChar == 't') {
aChar = '\t';
} else if (aChar == 'r') {
aChar = '\r';
} else if (aChar == 'n') {
aChar = '\n';
} else if (aChar == 'f') {
aChar = '\f';
}
out[outLen++] = aChar;
}
} else {
out[outLen++] = (char) aChar;
}
}
return new String(out, 0, outLen);
}
public static void main(String arg[]){
CharacterSetToolkit cst = new CharacterSetToolkit();
String unicode = cst.toUnicode("机构号只能输入数字", true); System.out.println(unicode);
}
}
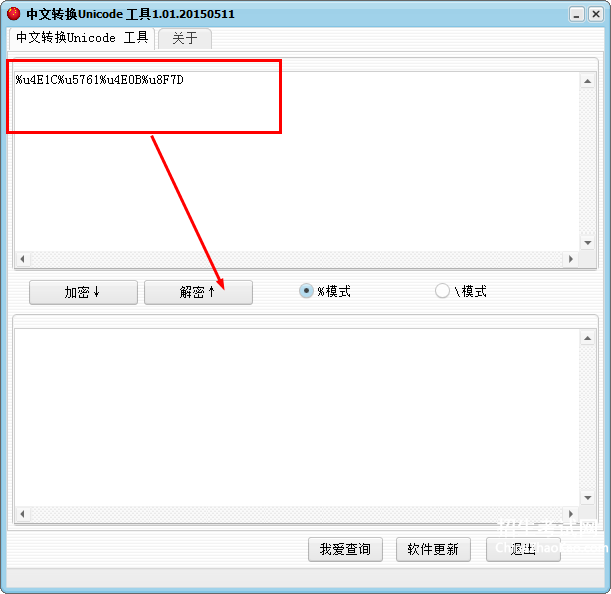
中文转为unicode编码
unicode编码转换器(二)
中文转为unicode编码
2008年04月21日 星期一 下午 01:42
什么是Unicode:
在创造Unicode之前针对各种语言有几百种编码系统,而且这些编码系统也相互冲突,给不同语言系统的电脑进行交流带来了麻烦。因为两种相同的字符在不同的编码系统可能有完全不同的意思,这些不同甚至会对电脑带来危害。于是Unicode出现了,Unicode给每个字符提供了一个唯一的数字,不论是什么平台,不论是什么程序,不论是什么语言。它真正实现了全球电脑系统的United,作为一个标准,它已经成为全球软件技术最重要的发展趋势。 为什么要把中文转换为Unicode
在互联网高速发展的今天,Unicode担当更重要的角色, 它比传统的字符编码更节省费用,使软件或者网站能够运用于不同的系统平台、语言和国家,而不需要重建,同时也保证了资料在不同系统中的完整性。所以说你只要将中文转换为Unicode,任何国家的人都能看到你想表达的真正意思,而不是乱码。
举例
中文原码(GB2312):叁肆伍陆柒捌
转为Unicode后: 叁肆伍陆柒捌网页效果为:叁肆伍陆柒捌
提示:改变网页编码为其它任何国家、语言的编码试试,始终能看见上面红色的Unicode中文。【unicode编码转换器】【unicode编码转换器】
JAVA:
将中文转为unicode 及转回中文函数
//转为unicodepublic static void writeUnicode(final DataOutputStream out, final String value) { try {
final String unicode = gbEncoding( value );
final byte[] data = unicode.getBytes();
final int dataLength = data.length;
System.out.println( "Data Length is: " + dataLength );
System.out.println( "Data is: " + value );
out.writeInt( dataLength ); //先写出字符串的长度
out.write( data, 0, dataLength ); //然后写出转化后的字符串
} catch (IOException e) {
}
}
public static String gbEncoding( final String gbString ) {
char[] utfBytes = gbString.toCharArray();
String unicodeBytes = "";
for( int byteIndex = 0; byteIndex < utfBytes.length; byteIndex ++ ) {
String hexB = Integer.toHexString( utfBytes[ byteIndex ] );
if( hexB.length() <= 2 ) {
hexB = "00" + hexB;
}
unicodeBytes = unicodeBytes + "\\\\u" + hexB;
}
System.out.println( "unicodeBytes is: " + unicodeBytes ); return unicodeBytes; }
/** *//***************************************************** * 功能介绍:将unicode字符串转为汉字
* 输入参数:源unicode字符串
* 输出参数:转换后的字符串
*****************************************************/ private String decodeUnicode( final String dataStr ) { int start = 0;
int end = 0;
final StringBuffer buffer = new StringBuffer();
while( start > -1 ) {
end = dataStr.indexOf( "\\\\u", start + 2 );
String charStr = "";
if( end == -1 ) {
charStr = dataStr.substring( start + 2, dataStr.length() );
} else {
charStr = dataStr.substring( start + 2, end);
}
char letter = (char) Integer.parseInt( charStr, 16 ); // 16进制parse整形字符串。 buffer.append( new Character( letter ).toString() );
start = end;
}
return buffer.toString();
}
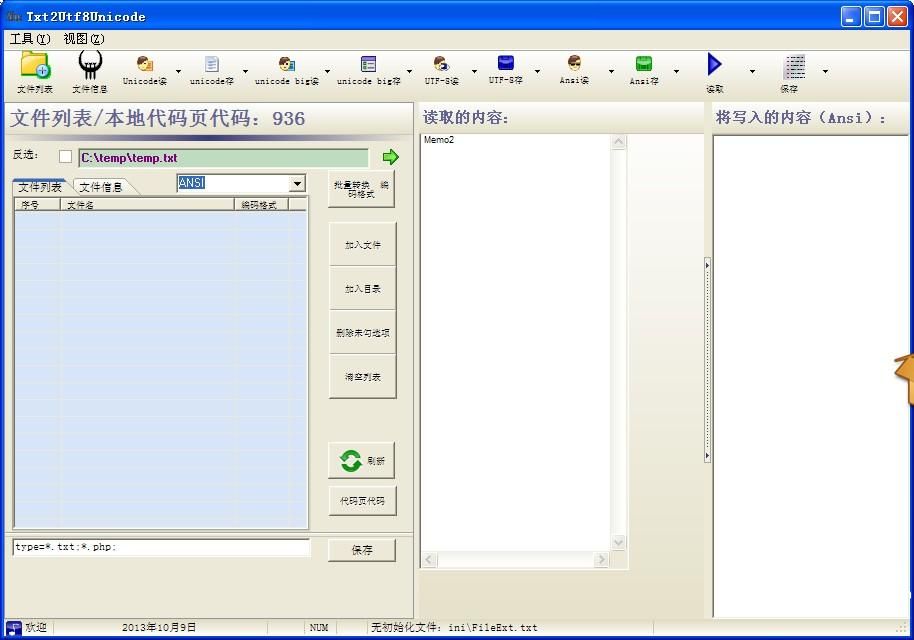
Java字符串取GBK,UNICODE编码和相互转换
unicode编码转换器(三)
package com.util;
import java.io.UnsupportedEncodingException;
import java.util.regex.Matcher;
import java.util.regex.Pattern;
public class conver_String_Hex {
/**
* @param args
* @throws UnsupportedEncodingException
*/
public static void main(String[] args) throws
UnsupportedEncodingException {
// TODO Auto-generated method stub
// 转换汉字为Unicode码
String s2 = "文1就是转换的标准";
System.out.println("s2: " + s2);
s2 = conver_String_Hex.stringToUnicode(s2);
System.out.println("s2_unicode_Hex: " + s2); // 转换Unicode码为汉字
String aaa =
"\\u4ec0\\u4e48\\u662f\\u5b89\\u5168\\u63a7\u4ef6" +
"\uff1f###\u5b89\u5168\u63a7\u4ef6\u53ef\u4ee5\u4fdd\u8bc1" +
"\u7528\u6237\u7684\u5bc6\u7801\u4e0d\u88ab\u7a83\u53d6\uff0c"
+
"\u4ece\u800c\u4fdd\u8bc1\u8d44\u91d1\u5b89\u5168"; System.out.println("aaa: " + aaa);
String s3 = conver_String_Hex.unicodeToString(aaa); System.out.println("s3: " + s3);
s2 = "文1就是转换的标准";
System.out.println("s2_src: " + s2);
s2 = conver_String_Hex.stringToGBK(s2);
System.out.println("s2_gbk_hex: " + s2);
}
/* * 把中文字符串转换为十六进制Unicode编码字符串 */ public static String stringToUnicode(String s) { String str = "";
for (int i = 0; i < s.length(); i++) {
int ch = (int) s.charAt(i);
if (ch > 255)
str += "\\u" + Integer.toHexString(ch); else
str += "\\" + Integer.toHexString(ch); }
return str;
}
/* * 把十六进制Unicode编码字符串转换为中文字符串 */ public static String unicodeToString(String str) {
Pattern pattern =
Pattern.compile("(\\\\u(\\p{XDigit}{4}))");
Matcher matcher = pattern.matcher(str);
char ch;
while (matcher.find()) {
ch = (char) Integer.parseInt(matcher.group(2), 16); str = str.replace(matcher.group(1), ch + ""); }
return str;
}
/* * 把中文字符串转换为十六进制GBK编码字符串 */ public static String stringToGBK(String s)
throws UnsupportedEncodingException {
String str = "";
for (int i = 0; i < s.length(); i++) {
String ch = String.valueOf(s.charAt(i));
// 取字符串编码示例 默认字符为GBK
byte[] sgbk = ch.getBytes("gbk");
String shex = "";
for (int j = 0; j < sgbk.length; j++) {
// System.out.println(sb[i]);
String hex = Integer.toHexString(sgbk[j] & 0xFF); if (hex.length() == 1) {
hex = "0" + hex;
}
shex=shex+hex;
}
str = str + " 0x" + shex.toUpperCase();
}
return str; }
}
.txt文本文档为什么打开是乱码
unicode编码转换器(四)
源文件根本就不是文本文件。"之后的名字,UTF-32三种这有两种情况:
扩展名,其中UTF-8是变长码,用来表明文件类型,所以需要修改扩展名)把源文件的扩展名改成了txt
注:文件名中最后的一个[,
由于解码错误,有些人出于保密或者网络传输方便(有些网络传输对格式有明确限制,导致了打开错误
你可以使用RTF(写字板)或者Word等软件打开
2:
编码方式由A耽臂蝗赚豪掉且SCII码和Unicode码
其中Unicode码包括UTF-8:
1